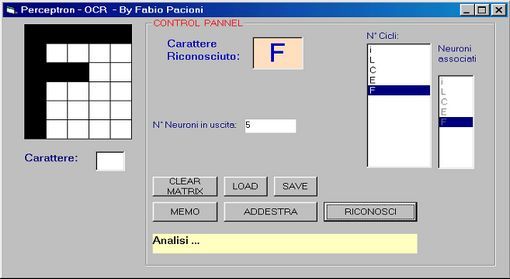
-Press the button to make the RICONOSCIMENTO
recognition. If all "smooth line" in the box Orange appear
the "F" letter.
You can try to design the "i" or "E" or "L"
or "C" to verify that the network can recognize these characters.
Finally, you can, try to ruin the characters in somewhere point to
see, until the network is able to discriminate a particular character.
OSS1:
The network is very rudimentary no software modules that perform
the auto center, scaling or rotation of characters and then, you must
draw ever to occupy the maximum space on the matrix. It 'also necessary,
and letters like "i", are always positioned it at the center
of the matrix!
curiosity
: The roto-translation operations are performed normally even when
we move our eyes. The recognition of a given image to be part of the
brain, in fact, must be independent from the position that the image
itself that occupies our retina. The biological organisms evolved,
like us, have developed a neural network can learn this transformation
from retinal coordinates to Skull Centric coordinates. This type of
network can be simulated artificially by a particular type of learning
by reinforcement. This is a variant of the algorithm (ARP-associative
Reward penality - Mazzoni, Andersen and jordan 1991)
Drawing from memory and character corruption
If you like, you can quickly draw a character by selecting from the
list of those available. To do this you must select a character from
the list that says "N. Cicli" The selected character will
be drawn directly into the matrix.
Now you can try to "destroy" the character to see how the
network is able to recognize it. Recognition, as before, is done by
pressing the "RICONOSCI" button
Network training
If you have not already tired , you can make another training (instead
of loading one with which I enjoyed myself).
Proceed as follows:
1.Re-Start program
2.Draw a character in the matrix
3.Insert in the text box, below the grid, the character you want
to associate. This will result in orange box.
4.Press "MEMO" to the association. The character will be
show in l"N° CICLI" and "NEURONI ASSOCIATI "
list box
5.Repeat steps 2,3,4 for each character to learn from the network
6.Press "ADDESTRAMENTO" key to train the network.
The training will be confirmed by the sentence:
"Addestramanto Neuroni Completato"
Verification:
You must verify whether the associations have been learned properly.
Select the first character from the list "N° Cicli"
and click "RICONOSCI". If the character that appears in
the orange box is correct go ahead and repeat the operation for the
next character. If the character is not recognized correctly, that
the network has failed to learn the transformation. It 'must therefore
provide another example of the same character. To do this, proceed
as follows:
1. Make sure that the specified character is displayed in the matrix
otherwise select it from the list "N ° cycles." Suppose
this is a "7".
2. Enter the "7" in the text box under the grill
3. Modify the "7" in the grid so as to provide a network
an example like the same character or leave unchanged the character
(unless you want the network should learn a variant on the question).
4. Press the "MEMO" to do the association (now in "N°.
Cicli" list are two examples for the same character).
5. Press trained to conduct the training.
6. Select either "7", then press the "RICONOSCI"
button and check if the character is recognized correctly. If not
we need to repeat this procedure until the character is recognized
correctly.
Once verified that all characters are recognized correctly if you
want to save the associations pressing the "SAVE" button.
The File Supply.txt will be update (or will be create a new one if
the file supply.txt does not exist). If we hold and not to lose the
file Supplì.txt on a previous training, rename the file Supply.txt
before with Supplyold.txt , for example. When you need to recharge
the old training will be enough to restore supplyold.txt its original
name!
NB: The list "N.Cicli" can be long at most 21 points
Network Limit
The neural network used is very simple (it is only one layer of neurons).
Increasing the number of characters increases the likelihood that
more neurons are working simultaneously in response to a given stimulus
input. This phenomenon is called interference. To remove it you must
submit to the network several times the same pair of training. In
this way, however, if by one hand increases the selectivity of the
network, the other hand will decrease the network capacity to generalize,
then decrease the capacity of the network to recognize corrupt characters!
To overcome these limitations is necessary to use a more powerful
neural network (but also more complex) as the Back Propagation.
Well the rest of article clarify the operation of the program and
the type of neural network used. About that I don't go into detail,
because it take me many pages and too long time. The Time is a precious
resource!
However for who not interested of technical aspects this article
finish here!
If you want instead take the path that I took myself, the madness,
go ahead and think no more!